
Est-il possible de déterminer à l’avance qu’un merge risque de poser problème ?
Auteurs
Nous sommes 4 étudiants en dernière année à Polytech' Nice-Sophia en informatique dans la spécialité "Architecture Logicielle":
Est-il possible de déterminer à l’avance qu’un merge risque de poser problème ?
Guillaume ANDRE guillaume.andre@etu.unice.fr
Alexandre HILTCHER alexandre.hiltcher@etu.unice.fr
David LANG david.lang@etu.unice.fr
Jean-Adam PUSKARIC jean-adam.puskaric@etu.unice.fr
III. Collecte d'information

Introduction
Ce document présente l'étude que nous avons menée dans le cadre du cours de Rétro ingénierie, maintenance et évolution logiciel du parcours Science informatique à Polytech Nice-Sophia. Cette étude porte sur la relation entre la qualité logicielle d'un projet et l'utilisation de Git merge au sein de ce dernier.
Lexique
Dans la suite du document, nous allons utiliser différents termes techniques qui seront définis ci-dessous afin d'éviter toute confusion.
Merge : Dans le monde de la gestion de version (avec Git par exemple) un merge, ou fusion en français, est le fait de fusionner deux branches afin d'obtenir un nouvel historique commun.
Comme dans l'exemple ci-dessus, lorsque les commits C de la branche topic et G de la branche master sont merge on obtient un nouveau commit H contenant les modifications faites sur la branche topic et la branche master.
Merge conflict : Un merge conflict est défini comme un merge qui entraîne la fusion d'un même fichier, entraînant l'apparition de marqueurs de conflit dans le cas où le merge ne peut pas être réglé automatiquement par Git
Qualité logicielle : L'IEEE définit la qualité logicielle en deux points : 1. Le degré avec lequel un système, composant ou processus répond aux exigences techniques spécifiées. 2. Le degré avec lequel un système, composant ou processus répond aux besoins et/ou aux attentes des utilisateurs.
Dans la suite de ce document, lorsque nous parlerons de qualité logicielle cela fera référence au point numéro 1. En effet, nous nous baserons sur des métriques de qualité logicielle fournies par des outils d'analyse de code. Nous ne tiendrons pas compte ici de la manière dont le système répond aux attentes des utilisateurs.
I. Contexte de recherche
Git est un outil de gestion de version libre utilisé par la majorité des projets open source. Aujourd'hui, utiliser Git pour gérer nos projets semble être une évidence, et il nous paraît intéressant d’analyser et quantifier l’impact de cet outil sur le code produit et sa qualité. Plus particulièrement nous nous intéresserons aux merges conflicts, qui sont une fonctionnalité de Git pouvant causer des problèmes sur le code (et parfois pour les relations humaines !). En effet, un merge conflict revient à fusionner des modifications concurrentes sur un même fichier, qui sont parfois des effets de bords résultants de modifications sur d'autres éléments (ex : un refactor d'un fichier fait avec un IDE). De plus, on peut trouver sur internet et dans la littérature de nombreux articles sur les bonnes pratiques de Git et comment bien réaliser des merge. Ceci montre bien que le merge est un problème récurrent pour les développeurs et utilisateurs de Git ou de système de contrôle de version. [2]
Dès lors il nous semble pertinent de nous demander quel est l'impact réel de ces merge conflicts dans les zones du code concernées par cette fonctionnalité, plus particulièrement vis à vis d'identificateurs de qualité logicielle précis : nombre de lignes, nombre de bugs, complexité cyclomatique.
II. Question générale
Lors de nos différents projets où nous avons travaillé avec git nous avons souvent eu des merges et des merge conflict. Suite auxquels il nous ait arrivé d'avoir des changements non voulus du comportement métier, du code moins lisible et une complexité accrue.
Nous cherchons donc à savoir si, pour un fichier d'un projet donné, il est possible d'établir une corrélation entre le nombre de merge conflict et la qualité logicielle. Si cette corrélation existe, il pourrait être possible de déterminer à l’avance qu’un merge puisse poser problème sur un fichier en mesurant au préalable sa qualité. Notre problématique générale consiste donc à déterminer si effectuer cette prédiction est possible. Si cette prédiction est possible, on pourrait alors envisager d'établir un processus ou une méthode de travail permettant de limiter les problèmes liés aux merges.
Pour répondre à cette question, nous avons choisi de répartir notre travail à travers plusieurs questions plus précises. Ces différentes questions abordent des axes différents de la relation entre qualité logicielle et les merges conflicts.
Est-ce qu’un fichier de mauvaise qualité logicielle aura beaucoup de merge conflict dans son historique ? Cette question porte sur l'impact de la qualité logicielle sur le nombre de merge conflicts. On souhaite déterminer si un fichier ayant une mauvaise qualité logicielle aura plus de merge conflicts dans son historique qu'un fichier de meilleure qualité.
Est-ce que les merge conflicts dégradent la qualité logicielle d’un fichier ? Dans cette question, nous abordons la question avec un axe différent, en effet, ici nous souhaitons savoir si à l'inverse les merges conflicts dans un fichier impactent la qualité logicielle.
Avec ces deux questions, on souhaite voir si la corrélation qu'on cherche à démontrer a plus ou moins d'impact dans un sens ou dans un autre.
 UCA : University Côte d'Azur (french Riviera University)
UCA : University Côte d'Azur (french Riviera University)
Sélection des projets à analyser
Les projets Git que nous allons analyser vont être extraits depuis la plateforme github. Elle nous semble idéale pour notre analyse étant donné le grand nombre de projets en libre accès qu'elle contient et la mise à disposition d'une API gratuite (bien que limitée). Nous cherchons dans les dépôts publics fournis par l'API, ce sont donc des projets publics ce qui pourrait conduire à plus de merges conflicts étant donné le plus grand nombre de contributeurs et la réduction de contrôle.
Nous avons de plus choisi d'appliquer d'autres restrictions afin de composer notre échantillon de projets :
Un certain nombre de commits et de merges minimums : cela permet d'exclure des projets ne possédant pas assez de merges dans leur historique pour être pertinents à analyser, étant donné que les merges conflicts sont longs à déterminer, nous nous basons sur les commits et les merges pour nous donner un bon indicateur.
Un langage de programmation commun, afin de pouvoir mesurer la qualité logicielle des différents projets de manière homogène. Nous avons choisi Java pour sa familiarité et sa compatibilité avec l'outil de mesure de qualité logicielle que nous avons choisi.
Extraction des merge conflicts
Une fois que l'on dispose d'un ensemble de projets Git, on peut facilement repérer quels commit sont des merge à l'aide de l'API github ou des commandes Git standard : il s'agit de commits avec 2 parents left et right. Pour identifier les merge conflicts, il suffit de rejouer le merge en question en 2 commandes Git :
git checkout leftgit merge right
On obtient alors l'ensemble des fichiers qui sont entrés en conflit, et si ces conflits ont été résolus automatiquement, nous permettant ainsi de mesurer le nombre de merges qu'a subi un fichier particulier sur l'ensemble de l'historique. Nous considérons les deux comme des merge conflict pour le contexte de notre étude.
Mesure de la qualité logicielle
Afin de pouvoir mener à bien notre analyse de qualité logicielle, l'outil que nous utilisons doit satisfaire plusieurs critères.
Nous allons devoir analyser un grand nombre de dépôts, et il doit donc être automatisable. Il doit également être capable d'effectuer des mesures à plusieurs échelles : celle du projet et du fichier, afin de pouvoir analyser séparément les éléments concernés par un conflit de merge et afin de pouvoir rapporter la qualité logicielle d'un fichier à la qualité logicielle générale du projet le contenant. Ces mesures doivent être récupérables de manière rapide afin de pouvoir analyser un grand nombre de fichiers.
Enfin, il est important que l'outil ait d'ores et déjà fait ses preuves afin de s'assurer de la validité des métriques mesurées.
Pour ces raisons, nous avons choisi d'utiliser l'outil SonarQube. Il dispose de plusieurs avantages :
Il est utilisé dans un cadre professionnel, avec l'usage de quality gates;
Il permet d'obtenir des métriques de qualité à l'échelle d'un seul fichier;
Il est compatible avec de nombreux langages de programmation, permettant la reproduction de nos expérimentations dans d'autres langages;
Il est facilement scriptable à l'aide de simple requêtes HTTP sur un serveur local déployé après l'analyse des projets
Métriques de qualité logicielles choisies
A l'aide de l'outil SonarQube, nous avons accès aux métriques suivantes :
Nombre de bug et code smells
Complexité cyclomatique par fichier et la complexité cognitive
Nombre de lignes et proportion de code dupliqué
Les métriques précedentes sont définies par Sonar de la manière suivante :
Bugs : Un problème qui représente quelque chose de mauvais dans le code, qui peut potentielement cassé. Exemple (Math should not be performed on floats):
Code smells : Un problème de maintenabilité dans le code. Exemple (for loop stop conditions should be invariant)
Complexité cyclomatique : La complexité cyclomatique est calculée en fonction du nombre de chemins possibles à travers le code. A chaque fois que le flux d'une fonction se sépare, la complexité est incrémentée de 1.
Complexité cognitive : La difficulté à comprendre le flux de contrôle. Voir le white paper sur la complexité cognitive pour plus d'informations [6].
Nombre de violations : Problèmes et bugs dans le code qui peuvent impacter l'exécution et la sécurité de l'application, on a plusieurs niveaux de violations, du plus grave au moins grave : Blocker, Critical, Major, Minor, Info.
Le nombre de bugs et code smells, ainsi que les différentes métriques de complexité, vont nous permettre de mesurer objectivement la qualité d'un fichier ou d'un projet. Ces métriques ont également l'avantage de ne pas être limitées à un langage de programmation particulier, ouvrant la possibilité pour la reproduction de nos expérimentations sur d'autres langages.
Afin de modérer l'impact que peut avoir la taille d'un fichier sur certaines métriques, nous allons les pondérer selon le nombre de lignes du fichier. En effet, il nous semble normal qu'un fichier de plusieurs centaines de lignes possède par exemple un nombre de bugs plus élevé qu'un fichier ne mesurant que 10 lignes.
IV. Hypothèses et expérimentations
Dans cette partie, nous allons décrire les différentes expérimentations que nous avons mis en place pour apporter des éléments de réponse aux sous questions que nous avons posées précédemment.
1. Est-ce qu’un fichier de mauvaise qualité logicielle aura beaucoup de merge conflict dans son historique ?
Nous avons l'intuition qu'un grand nombre de conflits sur un fichier va dégrader sa qualité, étant donné que cela implique à priori un grand nombre de modifications par des utilisateurs différents ne travaillant pas de manière totalement homogène (ou l'inverse, une mauvaise qualité logicielle implique que de nombreuses personnes doivent toucher au code). On s'attend donc à voir nos métriques mesurant le nombre de bugs et la complexité augmenter de manière proportionnelle au nombre de conflits qu'a subi un fichier dans son historique.
Afin de tenter de valider cette hypothèse, nous avons extrait et analysé 50 dépôts Github, analysé leur qualité logicielle en leur état actuel, puis extrait l'ensemble des conflits de merges à l'aide de la méthodologie décrite dans la partie précédente. Les dépôts ont été choisis aléatoirement parmi l'ensemble des dépôts Java disponibles sur Github.
Nous avons ainsi pu extraire 1609 merges, et analyser 267 conflits de merge. Nous avons donc pu exécuter SonarQube sur les différents projets ainsi récoltés afin d'en extraire des métriques de qualité logicielle sur le dernier commit. Une fois ces métriques extraites, nous avons pu les mettre en relations avec le nombre de merges présents dans l'historique des différents fichiers.
2. Est-ce que les merge conflicts dégradent la qualité logicielle d’un fichier ?
En suivant un raisonnement similaire à l'hypothèse précédente, un conflit de merge implique souvent des modifications par un développeur sur un code qu'il n'a pas écrit lui-même afin de résoudre le conflit. Pour nous, l'intuition est que cette action devrait mener à une baisse de la qualité du ficher.
Pour apporter des éléments de réponse à cette question, nous avons analysé 186 conflits de merge à travers 57 dépôts. Pour chacun de ces conflits, nous avons mesuré nos métriques de qualité logicielle sur les fichiers concernés avant et après l’occurrence du merge.
V. Analyse des résultats
1. Est-ce qu’un fichier de mauvaise qualité logicielle aura beaucoup de merge conflict dans son historique ?
Après notre expérimentation, un problème rend l'analyse des métriques collectées difficile. En effet, on remarque que le nombre de conflits de merge par projet est en général très faible : en moyenne, on obtient ainsi une dizaine de conflits pour plusieurs milliers de fichiers. Ces conflits ont également tendance à être répartis sur de nombreux fichiers, ce qui rend la présence de fichiers avec 2 ou plus conflits de merge dans leur historique rare et complique ainsi l'observation d'une tendance.
Ce problème est présent même sur les projets de plus grande taille, comme nous avons pu le constater par plusieurs exécutions de notre expérimentation avec des échantillons de dépôts différents. On peut émettre comme hypothèse que les dépôts plus grands ont tendance à limiter intentionnellement le nombre de conflits dans leur démarche de travail. Pour cette raison, il est impossible d'observer des résultats sur l'évolution de nos métriques en fonction du nombre de conflits de merge sur un dépôt unique. Il existe d'ailleurs des dépots avec des milliers de commits mais aucun conflits
Afin de pouvoir observer un résultat, nous avons donc dû rassembler l'ensemble des fichiers concernés pour chaque métrique pour plusieurs dépôts. Or, cette approche est biaisée par le fait que le niveau de qualité logicielle moyen entre plusieurs projets peut fortement varier : un fichier de haute qualité pour un dépôt peut être considéré comme un fichier de basse qualité dans un autre.
Les différents graphiques ci-dessous présentent les résultats que nous avons obtenus en sur un ensemble de 50 dépôts Github. Il est important de noter que dans les graphiques suivants, sauf pour le premier, les valeurs présentées sont pondérées par le nombre de ligne contenu dans les fichiers.

Si on regarde la tendance que présente ce graphique on peut voir qu'en moyenne un fichier qui a plus de merge conflict dans son historique contient plus de lignes.

Tendance : f(x) = 0.132x + 0.255 Comme on peut le voir sur le graphique le nombre de bugs augmente peu lorsque le nombre de merge conflicts augmente. Ceci est confirmé par la courbe de tendance dont le coefficient directeur est a = 0.132, ce qui assez proche de 0.

Tendance : f(x) = 0.322x + 16.972 Comme on peut le voir sur ce graphique, la courbe de tendance est quasiment constante. En effet, le coefficient directeur est de 0.322 ce qui encore une fois est très faible. Ceci signifie donc que le nombre de code smells n'augmente presque pas lorsque le nombre de merge conflicts augmente.

Tendance : f(x) = 12.661x + 55.691 On peut remarquer, ici, que le merges conflicts ont une forte influence sur la complexité cognitive d'un fichier, en effet, le coefficient directeur est de 12.661.

Tendance : f(x) = 1.56x + 50.803 Pour ce dernier graphique, le coefficient est certes bien moins important que sur le précédent, mais il n'en reste pas moins significatif.
D'après les données présentées ci-dessus, on peut dire que le nombre de merge conflicts n'influe pas sur le nombre bugs et de code smells mais influe plus fortement sur la complexité et la complexité cognitive. On peut donc dire que le merge conflicts rendent le code plus complexe à lire et à comprendre mais n'ajoutent pas vraiment de bug ou de code smells. Cette conclusion est toutefois à mitiger, en effet, comme on peut le constater sur les différents graphiques, nous avons peu de données pour les fichiers ayant plus de 4 merges conflicts dans leurs historiques.
Le véritable problème de cette approche en l'état actuel est que la proportion de merges conflicts par rapport au nombre de fichiers et minime, moins de 1% en général. Et on observe que le nombre de fichiers contenant n merge conflict se réduit drastiquement au fur et à mesure que n augmente, ce qui rend l'analyse d'autant plus compliquée.
Enfin, une observation intéressante que notre analyse de nombreux projets a permis d'observer, et que l'on ne peut pas voir sur les graphes, est que les fichiers contenant le plus de merge conflicts dans leur historique ne sont en général pas des fichiers de code, mais des fichiers de configuration. Par exemple sur de nombreux projets Java utilisant maven analysés, on remarque des pom.xml avec 5 ou plus merge conflict. On peut supposer que cela est dû à l'ajout de bibliothèques ou simplement à des changements de version concurrents.
2. Est-ce que les merge conflicts dégradent la qualité logicielle d’un fichier ?
Pour répondre à cette deuxième question nous avons analysé 57 projets contenant 186 conflits sur 328 fichiers. Pour chacun des conflits nous avons analysé les fichiers concernés avant et après le merge conflict. Les graphiques suivants présentent les résultats que nous avons obtenus.

La couleur des barres indique si la métrique a une évolution positive en vert (moins de bugs, plus de documentation...) ou une évolution négative en rouge (plus de complexité, plus de lignes de code) du point de vue qualité. On a en gris les métriques n'indiquant pas réellement une variation dans la qualité du code (nombre de lignes et de commentaires).
Ce graphique nous montre qu'en moyenne l'ensemble des valeurs mesurées augmentent après un merge conflict. On peut aussi notament remarquer que la complexité augmente de 5.26% et la complexité cognitive de 5.71%. Ceci viens donc confirmer ce que nous pensions dans la partie précédente : les merge conflicts font augmenter la complexité et la complexité cognitive. On peut de plus noter que le nombre de bug ne change pas et que le code smells augmente de 3.89%. On voit donc ici que globalement la qualité après une merge conflict est moins bonne que la qualité avant celui-ci.
On peut donc conclure (sur le dataset analysé) que nous avons bien une corrélation entre l'apparition de merges conflicts et une diminition de la qualité logicielle. Cependant, nous ne pouvons en aucun cas conclure à un lien de causalité entre ces deux paramètres. En effet, cela peut être dû à un delta important (beaucoup de commits et d'ajouts / suppression de code) entre le commit de base et le commit résultat. De plus, nous ne voyons pas dans cette étude les merges qui aurait pu apparaitre dans des git flow de type rebase [7]. Or il est possible qu'un git flow puisse influer sur la qualité du code ou qu'il soit utilisé uniquement par des développeurs confirmés.
Les graphes ci-dessous présentent l'ensemble des mesures de différence des métriques mesurées avant et après un conflit de merge.

Métrique
Ajout de lignes
Ajout de lignes commentées
Minimum
-421
-13
1er quartile
2
0
Médianne
11
0
3ème quartile
36
3
Maximum
911
82
Les données présentées ci-dessus nous montrent que dans la moitié des cas traités le merge ajoute entre 2 et 36 lignes au fichier.
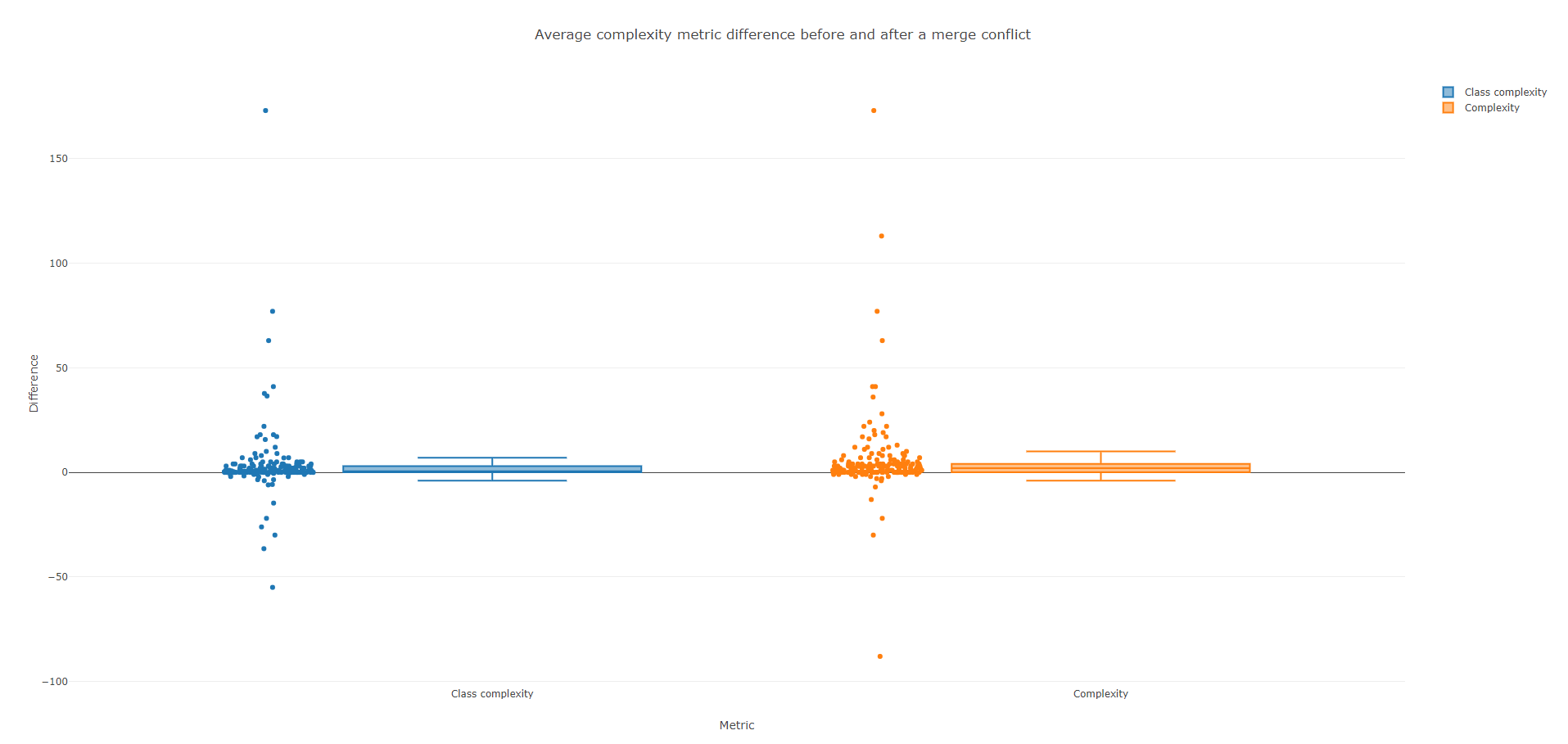
Métrique
Complexité de la classe
Complexité
Minimum
-55
-88
1er quartile
0
0
Médianne
0.5
2
3ème quartile
3
4
Maximum
173
173
Les données ci-dessus nous permettent de relativiser l'augmentation moyenne de 5.26% de la complexité après un merge conflict. Comme on peut le voir ici, en réalité, la complexité n'augmente que très peu dans la plupart des cas et elle diminue même dans certains cas. En effet, il n'y a que 25% des merges qui font augmenter de façon significative la complexité
VI. Conclusion
Nous avons pu voir qu'il est très difficile de trouver une tendance entre la qualité logicielle et le nombre de merge d'un fichier étant donné la rareté croissante des fichiers ayant subi un grand nombre de merge conflict
Ce problème ne s'applique toutefois pas si on regarde la qualité logicielle d'un fichier avant/après un merge conflict puisqu'on peut calculer cette métrique peut import le nombre de merge conflict effectués au cours de la vie d'un fichier. Ce que les résultats nous montrent est qu'il semble bien exister une corrélation entre la qualité logicielle et les merge conflict, avec une augmentation des indicateurs de mauvaise qualité logicielle d'environ 5% en moyenne. Notons bien que nous calculons la valeur relative de ces indicateurs, il ne s'agit donc pas simplement que les fichiers contiennent plus de code de qualité équivalente en moyenne, mais bien que la qualité moyenne du fichier a baissé après le merge conflict.
Il serait toutefois judicieux d'approfondir les recherches afin de trouver de façon précise la raison de ces résultats. Il serait possible d'essayer de mettre en relation le nombre de commits entre les commits base et result d'un merge lorsqu'il y a un conflit et l'augmentation ou la diminution de la qualité logicielle. Finalement, il serait très intéréssant d'évaluer l'impact d'un git flow sur celui du merge conflict sur le code.
En l'état nous ne pouvons pas réellement savoir à l'avance si un merge risque véritablement de poser problème. Malgré tout, on peut voir dans nos résultats les métriques les plus critiques à observer lors d'un merge conflict, notamment les violations de type blocker ou info. Il est en effet possible qu'un merge conflict cause une augmentation de ces problèmes, donc un fichier qui subit déjà ces problèmes devrait dans l'idéal au être réusiné avant le merge afin d'éviter de l'empirer.
VII. Outils
Dans cette partie, nous allons brièvement décrire l'ensemble des scripts que nous avons développé afin de pouvoir conduire nos expérimentations. Des instructions plus détaillées sur leur usage sont disponible dans le dépôt github les contenant [5]:
file-quality-analyser exécute un sonar-scanner sur un projet si cela n'a jamais été fait. Il permet ensuite d'extraire des métriques de qualité logicielle pour un fichier d'un projet donné;
graph-generator génère des graphiques présentant les métriques de qualité logicielle en fonction du nombre de merges pour les différents fichiers analysés;
merge-conflict-extractor permet de rejouer les merges et de déterminer quels conflits ont eu lieu sur quels fichiers;
merge-extractor permet de cloner et récupérer l'ensemble des merge des dépôts;
quality-before-after permet pour chaque merge-conflict d'extraire
par chaque fichier les métriques de qualité logicielle avant et après le merge;
quality-analyser permet l'analyse des dépôts et la collecte de métriques sur les fichiers concernés par les merge;
repository-finder utilise l'api github afin de récupérer un échantillon aléatoire de dépôts selon les critères passés en paramètre;
VIII. Références
[1] Présentation de l'IEE sur la qualité logicielle :
[2] Articles en liens avec la qualité logicielle et l'utilisation de banche/merges :
[3] Outil SonarQube:
[4] Best practice git merge :
[5] Dépôt contenant les scripts pour reproduire l'expérimentation:
[6] White paper de sonarsource sur la complexité cognitive
[7] Article sur l'utilisation de la commande rebase dans workflow git
Last updated
Was this helpful?